Mender blog

Mender project provides proof that golang and microservices architecture make a good pair. Together with MongoDB, web UI, and a bit of orchestration they are building blocks of a modern highly scalable and customizable over-the-air (OTA) software update solution. In this post I describe the challenges we faced in the implementation of one of the core elements we changed, one way of migrating to a new MongoDB driver.
Why did we do it?
The community driver for MongoDB (referred to as mgo) has been pretty stable and provided a solid, functional, and safe interface for all operations. Mender has used it for years and we have not seen even one real problem within the driver (lack of retries being a small exception from this rule). The reasoning behind the answer to “why even touch it then?” is based on the observation that mgo has become virtually unmaintained, and on the other hand on the fact that MongoDB 3.4 reaches end-of-life in January 2020. Both of those factors contributed to the decision to migrate to officially supported driver (mongo-driver) which aligns with near-future plans of using MongoDB v4. Although mgo supports v3.6 it seems better to perform migration from v3.4 to v3.6 and then to v4 already with the new driver in place. Keeping in mind that MongoDB is the only persistent storage for Mender 6 core micro services, it may seem a risky and difficult task. We would like to prove it otherwise. Below we will show how the Mender code was changed to support new driver, then continue to show the results of benchmarks, and discuss how we solved this challenge.
A dive into the code
What does it take to migrate to mongo-driver?
Context
The general rule with mongo-driver is that context is passed to every operation. When one does some design it is best to take it into consideration. When you have context already and you use it, it is worth thinking about propagating it down to the mongo calls. What looked like this with mgo:
//mgo
_ = collection.Find(query)Now takes extra first argument:
//mongo-driver
_, _ = collection.Find(ctx, query)Taking a look at the driver code the passing of context to every call makes sense, it can contain a session.
Connection
The first difference one is bound to encounter is the connection handling. In mgo there was the concept of one master session from which all session where copied on demand and closed after they were not used any more. The typical sequence with mgo looked like that:
//mgo
masterSession, err = mgo.DialWithInfo(dialInfo)
s := db.session.Copy()
defer s.Close()With mongo-driver this is changed to:
//mongo-driver
clientGlobal, err = mongo.Connect(ctx, clientOptions)
/*then, when the need to perform an operation comes, just reuse existing client:*/
collection := db.clientGlobal.Database(mstore.DbFromContext(ctx, DbName)).Collection(DbDevicesColl)And as long as MongoDB is in use so is the client instance. This change of topology have potential important and far-going consequences. There is a question what happens to the data consistency when you perform many read/write operations in one or many routines. This case will be discussed below.
Basic operations: Find, Insert, Update, Delete, Aggregate
The basic operations of Find, Update, Delete, take a slightly different form. As a general rule the results of insert, update, and delete are returned alongside the error, which on the one hand makes it easier to access the inserted ids for instance, but is an extra thing to remember and can be a bit of a nuisance when one is not interested in the results of the call. What with mgo looked like that:
//mgo
var groups []model.GroupName
//Find
err := c.Find(bson.M{}).Distinct("group", &groups)
//Insert
err := c.Insert(d)
//Update by id
err := c.UpdateId(id, bson.M{"$set": &model.Device{Group: newGroup}})
//Delete by id
c.RemoveId(id)With mongo-driver the above takes the following form:
//mongo-driver
filter := bson.M{}
results, err := c.Distinct(ctx, "group", filter)
c := db.client.Database(mstore.DbFromContext(ctx, DbName)).Collection(DbDevicesColl)
//Find
var res model.Device
cursor, err := c.Find(ctx, bson.M{DbDevId: id})
//Insert
_,_ = collection.InsertOne(ctx, d)
//Update
res, err := c.UpdateOne(ctx, filter, update)
//Delete
result, err := c.DeleteOne(ctx, filter)The whole family of functions that operate on ids (FindId, UpsertId, etc) e.g.:
//mgo
_, err := c.UpsertId(dev.ID, update)is no existent in mongo-driver and has to be replaced with:
//mongo-driver
res, err := collection.UpdateOne(ctx, filter, update, options.Update().SetUpsert(true))The Pipe call was replaced with Aggregate. Let’s assume we have the following pipeline:
go
project := bson.M{
"$project": bson.M{
"arrayofkeyvalue": bson.M{
"$objectToArray": "$$ROOT.attributes",
},
},
}
unwind := bson.M{
"$unwind": "$arrayofkeyvalue",
}
group := bson.M{
"$group": bson.M{
"_id": nil,
"allkeys": bson.M{
"$addToSet": "$arrayofkeyvalue.k",
},
},
}In mgo it may be executed with:
//mgo
c := s.DB(mstore.DbFromContext(ctx, DbName)).C(DbDevicesColl)
pipe := c.Pipe([]bson.M{
project,
unwind,
group,
})
type Res struct {
AllKeys []string `bson:"allkeys"`
}
var res Res
err := pipe.One(&res)And with mongo-driver it can be written as:
//mongo-driver
cursor, err := c.Aggregate(ctx, []bson.M{
project,
unwind,
group,
})
defer cursor.Close(ctx)
cursor.Next(ctx)
elem := &bson.D{}
err = cursor.Decode(elem)
m := elem.Map()
results := m["allkeys"].(primitive.A)Where primitive.A is the piece not to be forgotten about. In case one got tempted and used []interface{} here, which by definition is primitive.A, the following runtime error will be reported:
pretext
panic: interface conversion: interface {} is primitive.A, not []interface {}Due to the fact that the driver does not expose the true definition of the primitive.A type. As can be seen the changes are not drastic, and can be easily introduced, but automating it would take a considerable effort.
Data consistency and sessions
As mentioned already mongo-driver holds client object at all times and it is reused across all calls and should be closed (Disconnect) only when we are done with persistent store. This is a major difference as compared with mgo idea of session-copying on demand and closing it after we are done with the operation(s) at hand. Theoretically when running many operations of find, update, delete, one should take caution and use mongo-driver sessions as the below example shows:
//mongo-driver
sessionOptions := options.Session()
sessionOptions.SetCausalConsistency(true)
sessionOptions.SetDefaultReadConcern(readconcern.Majority())
sess, err := db.client.StartSession(sessionOptions)
defer sess.EndSession(context.Background())
err = mongo.WithSession(context.Background(), sess,
func(sessCtx mongo.SessionContext) error {
database := db.client.Database(name)
c0 := database.Collection(colleciton0Name)
c1 := database.Collection(collection1Name)
err := c0.FindOne(ctx, model.UserFilter{Name: username}).Decode(&user)
cursor, err := c1.Aggregate(ctx, pipeline)
})The above can have marginal influence but also could become critical, e.g., when there is existing code which expects certain data consistency and both the driver and the database get an upgrade. It can matter especially now that 3.4 reaches end of life, and there were major changes in the way sessions are handled in later versions.
Benchmarking Drivers
Since not only the driver itself is new and interface is different, but also the mongo store module lies in the center of Mender, it seems like a good idea to perform at least basic benchmarks. Few examples are shown here.
Basic operations We tested briefly some of the most common operations, to see how the new driver works. Every run consisted of freshly started clean MongoDB instance and the same go code running either mgo or mongo-driver calls. Even when the only parameter was the number of records inserted, every time new MongoDB instance was started.
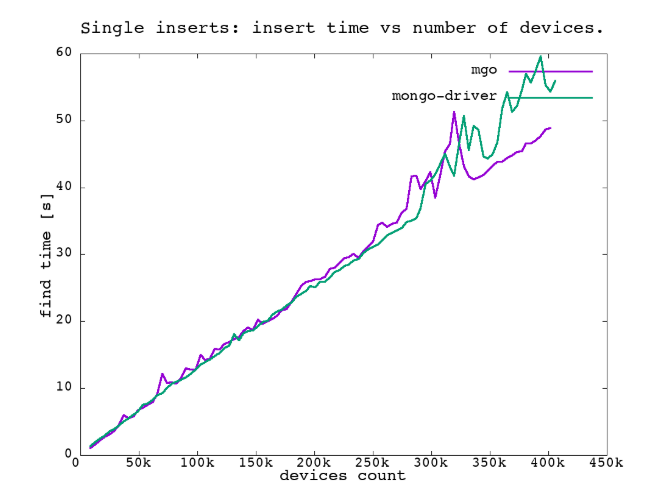
Single inserts
The simplest benchmark imaginable is probably: insert documents one-by-one and measure the time it takes to do it. That is what we also did, and here are example results. The figure shows time needed to insert all elements of an array. There are no big surprises here.
Bulk inserts
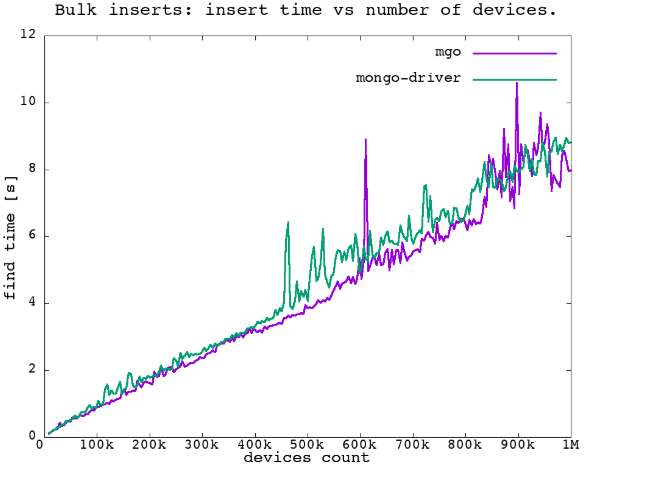
mgo has a nice feature with regard to batch inserts. Insert of multiple documents, if it is possible to collect them in arrays, looked like that:
//mgo
b := c.Bulk()
for _, metric := range metrics {
b.Insert(metric)
}
_, err := b.Run()With mongo-driver it can be done with:
//mongo-driver
var buffer []interface{}
buffer = make([]interface{}, len(metrics))
for i, s := range metrics {
buffer[i] = s
}
result, err := c.InsertMany(ctx, buffer)Since it is one of the most basic usages, very often needed, we performed some benchmarks, and the results can be seen in the below figure. The apparent lower performance of the mongo-driver can be accounted for by the need to copy the array into an array of interface{}.
FindMany
In the same way query of multiple documents can be tested. In this scenario there were 8388k (globalLimit below) records inserted into the test database, and then they were being retrieved via Find, and deviceCount was a parameter for the plots:
//mgo
l0:=int(float64(globalLimit)*0.5-float64(deviceCount))
l1:=int(float64(globalLimit)*0.5+float64(deviceCount))
q := bson.M{
"index":bson.M{"$gt":l0,"$lt":l1},
}
var result *DeviceBenchmarkRecord
iter := c.Find(q).Iter()
for iter.Next(&result) {
}And with mongo-driver:
//mongo-driver
l0:=int(float64(globalLimit)*0.5-float64(deviceCount))
l1:=int(float64(globalLimit)*0.5+float64(deviceCount))
q := bson.M{
"index":bson.M{"$gt":l0,"$lt":l1},
}
cursor,err := c.Find(ctx,q)
for cursor.Next(ctx) {
var d DevicebenchmarkRecord
cursor.Decode(&d)
}The plot data was acquired by running the Find with increasing deviceCount, to query more and more devices (each device has got assigned a unique index field on insert to the test db).
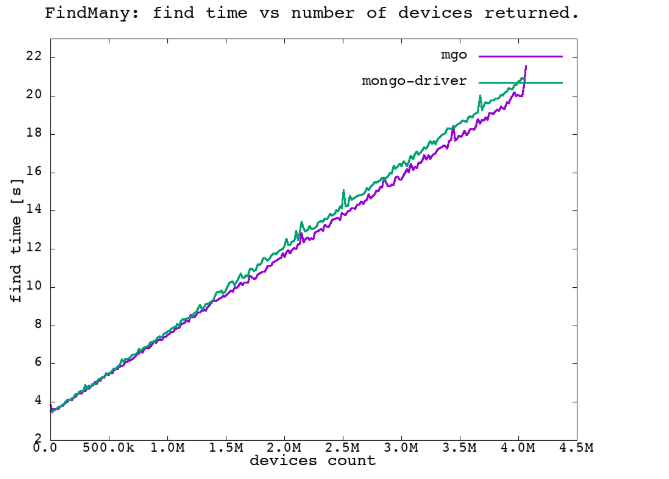
This time mongo-driver with the increasing number of records returned tends to diverge from the apparently better performance of mgo in this case.
Inventory service
Mender inventory service is the one that uses persistent db storage the most. It is the source of knowledge about devices, provides endpoints for grouping, paging, and searching, as well as stores devices attributes. This was the first one to be migrated to mongo-driver and it was the one that underwent first benchmarks in order to find out how the new driver performs in real life. Present benchmark can be considered a test between mgo Pipe and mongo-driver Aggregate since those calls are in the heart of GetDevices function which was called via device inventory API in present scenario.
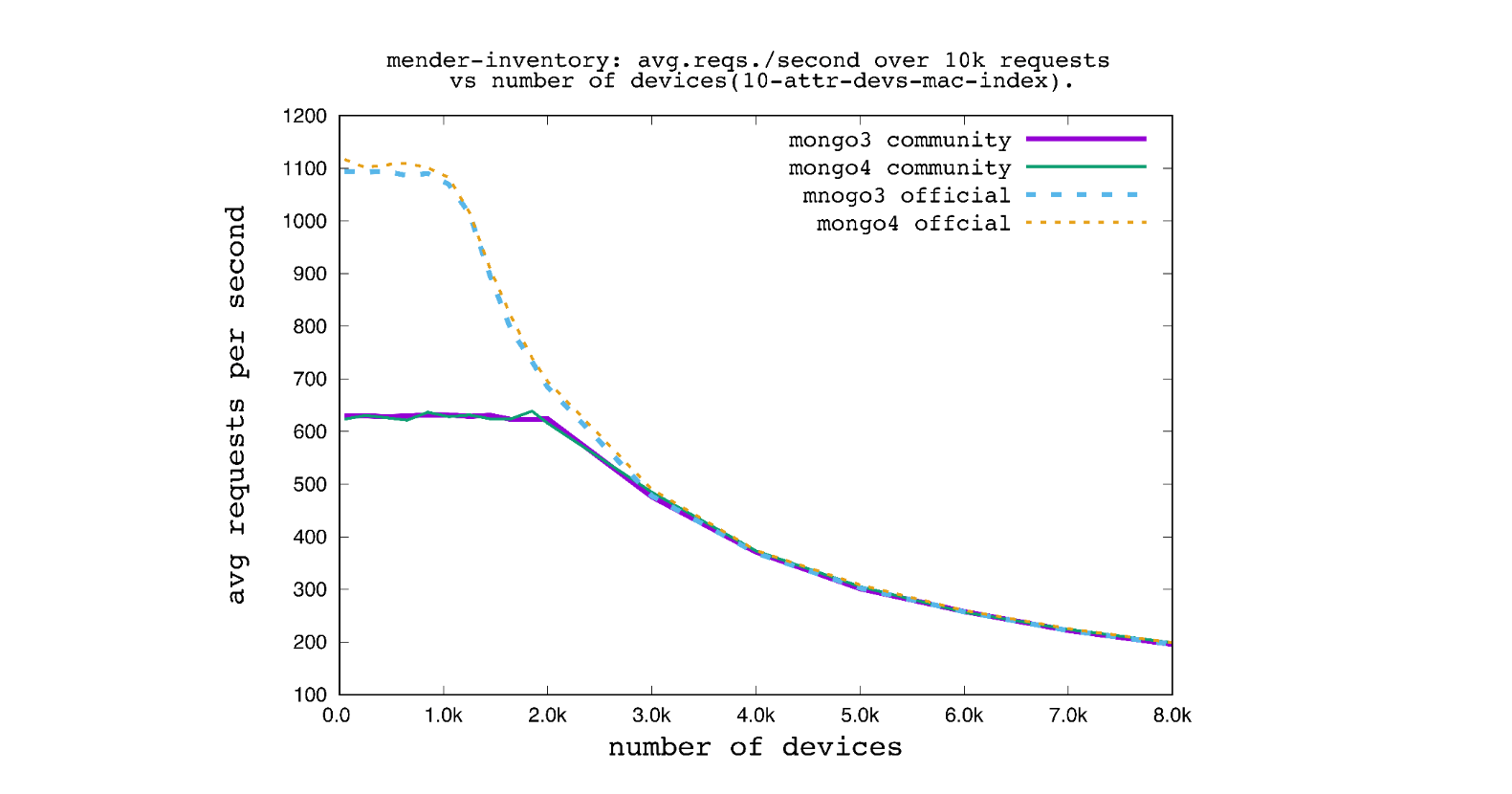
The above figure shows the results of one of the test scenarios as average requests per second vs number of devices in the database. The average is calculated by running 10k requests executing a HTTP GET to find devices by mac address being one of the 10 attributes. It actually uses one of the experimental features of inventory service: searching by regular expression. All attributes are indexed in this case. The dashed and solid lines denote mongo-driver and mgo, respectively, while thick lines stand for MongoDB v3.4 and thin ones for MongoDB v4.2. As can be seen there is a certain region (in terms of device count below 2.5k) where mongo-driver performs significantly better than mgo, while above 3.5k the performance and scaling is comparable.
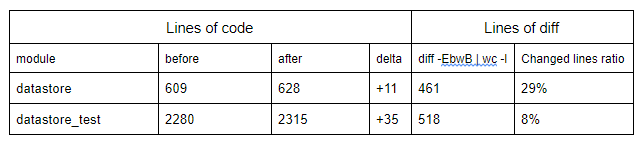
In the above data_store stands for the main module that handles all db operations, and data_store_test are the unit tests. The “changed lines ratio” was calculated as the number of lines that were reported as changed by the diff command, divided by the number of lines before the migration. The new API does not introduce a considerable overhead as can be seen from the above; the amount of code in the main module and in the unit tests did not increase significantly. However the size of diff for the data store main module compared to the number of lines of code before migration is large. The changes occurred on 178 lines of code (taken from diff -EbwB) in the data store after migration. If we divide that by the total number of lines of code when old driver was in use, we can see that roughly 30% of the code had to be changed. This includes trivial changes like context propagation across the calls.
Summary
Performance
The official driver does not perform drastically worse than the community one, at least in most cases we could test. Surprisingly, it does show slightly lower performance in ‘bulk inserts’ (partly due to extra copy to []interface{} array) and ‘find many’ scenarios, but makes up for it in a real-life case of regular expressions search, group, and paging with Aggregate pipelines. All of the scenarios we studied indicate that is not easy to beat the performance of the community driver. It has been around for a long time and many talented people worked on it.
Usage
Every call from the community driver has a counterpart in the official driver API, or there is an easy way to port your code to mongo-driver. At the same time the API is flexible, logical, and usable, which makes the overall experience a rather pleasant one. The migration case proved once again that having a separate module to handle persistent storage is always a good idea. One may also wonder if an extra layer of abstraction should not be given some consideration when designing a piece of software that uses the database. Call to “saveDevice” could call “persistentStorageSaveDevice” which could call “mongoDBPersistentStorageSaveElement”. In that case the migration would be just to replace lowest “wrappers” around db-specific calls.
Main differences
The most notable issues we encountered during the migration due to the differences between the drivers were: Context passing in every call, global client, session handling, and performance (as indicated by benchmarks above).
They were not blockers but merely items to take into account when code was ported to the new driver, as they should also be when new design is created.
Wrapper or migration tool
There is a ticket in mongo-driver tracker that specifically requests a tool to easily migrate to the new driver. Out of the two implementation alternatives mentioned there, the code rewrite tool seems like a huge project which is bound not to work in moderately obfuscated code, while the other one: API shim is a possibility which can influence performance. Taking into account the time needed to implement either one of them, we decided that direct modifications in the store modules is probably the best option.
With new MongoDB v4 around the corner, 3.4 reaching end of life, and major changes in session handling in 3.6, now seems like a good time to migrate as mongo-driver is mature enough and works well enough in most cases. It makes more sense to hit the 3.6 already with new driver and deal with new sessions with it, especially that there are no guarantees that existing code using mgo would not have had to be changed. The community will most certainly benefit from the fact that golang got an officially supported driver which will change the dynamics of the go and MongoDB pair in the modern world.
Thanks to Alf-Rune Siqveland for providing mongo-driver sessions example and useful discussions.
Peter Grzybowski (Mender.io)
Recent articles

Containerized software updates: How machine-agnostic infrastructure unleashes smart products for all
Discover how machine-agnostic infrastructure enables seamless software updates for AI-driven IoT devices, enhancing innovation and market reach across diverse environments.

Ambition is outpacing preparedness: Immature infrastructure projected to fail within five years
Explore the growing complexity of IoT device management and the challenges OEMs face with infrastructure, compliance, and product launches in the latest industry report.

The EU CRA regulation: Three key considerations any international company needs to know
The EU Cyber Resilience Act (CRA) requires a holistic approach to security compliance for connected products. Discover key considerations from Northern.tech and STMicroelectronics.
Learn why leading companies choose Mender
Discover how Mender empowers both you and your customers with secure and reliable over-the-air updates for IoT devices. Focus on your product, and benefit from specialized OTA expertise and best practices.
